Those wings... I want them too.
про Data Science-соревнования на английскомAgain, my regular Diary posts were constantly deferred in the last month, as well as many other regular activities, due to participation in data science contests. Actually, in two of them.
Participation in the first was obligatorily as a homework on the free courses Data Mining in Action that I have been attending recently. The competition was held on the popular Kaggle platform and was called Data Science Bowl 2018:

Well, I will post one more picture from the competition:

The task was to train an algorithm that automatically locates the nuclei on the microscope photos of biological cells. It should help in the medicine, allowing to develop new drugs faster and treat diseases more effectively.
The level that was required by our homework at first looked very ambitious, as we have to achieve 0.45 metric score. Sure, this number itself does not telling a lot. So, to explain, there were about ~3000 participants in the stage 1. Places of those who earned 0.45 and higher were starting from about ~200. Thus, 200/3000 ~= 0.067. How does it sound to get into the top 6% of huge international Deep Learning competition on the most popular data science platform?
The reality turned out to be not so scary. In fact, Kaggle is not only a competitive platform but also a great place for information exchange and education. Many participants share their solutions, approaches and ideas. Our courses' organizers recommended us to use one of the available models, configure it by ourself and train it up to the desired level. They pointed out a model that gave required scores for sure, the custom implementation of Mask R-CNN architecture, proposed by Facebook Research. Though the choice was not limited to this only variant, I've decided not to risk and took this implementation. Apart from this and others realizations of Mask R-CNN, one more architecture that showed high results was U-Net, often used for biological tasks. (And that was the architecture used by the won team).
Thus, my aim was to set up the code and make it run, not to develop the algorithm from the beginning. However, this task is not done in three clicks too!
Training neural networks for computer vision is very computationally intensive. It is not usually performed on the CPU, but rather on powerful GPU, with such technologies as NVIDIA CUDA. My simple home computer just has not the capacities required. For other homeworks we used to work with Google Colaboratory. It is absolutely free online tool, but it is a little bit limited. I found no opportunity to handle the environment in a custom way, to install libraries from sources and to build extensions. Every twelve hours the runtime is reset, and you have to perform the setup from the beginning. And also, there can be technical failures, as in many other free resources.
The only decision that I saw, was to turn to cloud computing and rent a virtual machine. Amazon has images specialized for deep learning, having a lot of useful frameworks preinstalled. They are called Amazon Deep Learning AMI. Such virtual machines are not free, with per-hour fee, but when you are participating in a popular competition, there's no surprise that you have to pay.
It took several days and a fair amount of brainwork to install the solution, to tune the code and to train the model, however I've managed to get the needed score:
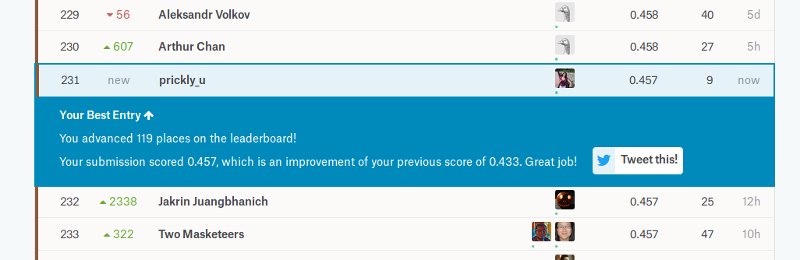
It cost me about $60, and the unpleasant thing was that 18% (almost one fifth!) of this sum was just the VAT, the tax that I had to pay in favor of the Russian Federation. What for? What Value-Added it was? I was just using the service of a foreign company in educational purpose, to learn how to solve a biomedical task. For me it looks like a punishment for Russian citizenship from Russian country. Here can be added the recent appreciation of the dollar along with Roskomnadzor blocking bunches of Amazon IP addresses. And the prohibition of Telegram, where our courses' chats lived. Are my thoughts to leave this place really unjustified?
The DMiA's teachers fucked up with the deadline a little. They declared that the homework had to be finished until the 17th of April, the next day of the competition end. However, the competition had two stages, and scores on the leaderboard were shown only for the first one. The second stage scores became available only when the stage ended, so there were no possibility to make sure that you managed to get the needed level. Thus, the deadline was denounced as 17th of April, but in fact it was the 11th of April, and that was discovered not so early. We've discussed it n the group chat, I've finished my work in time and not sure if anyone else was affected, but that was not a good situation. Yeah, it's IT, shit happens here constantly, I know.
Even Kaggle competition organizers make mistakes. There was a paragraph in the rules that stated: «Stage one deadline and stage two data release: April 11, 2018 - PLEASE NOTE: If you do not make a submission during the second stage of the competition, you will not appear on the final competition leaderboard and you will not receive competition ranking points». There was also mentioned that the participants have to finalize their models till April 11 - and no clarification, that did it mean. So I've uploaded answers for stage 1, uploaded answers to stage 2, and only after the competition ended I've learned that we had to upload the model source code as well - otherwise such participants were removed from the final list. Fortunately, I was not the only sufferer, there were a lot of complaints. Organizers agreed that it was their fault and restored all the places.
I've counted to stay int the "bronze" area, as I was there on the stage 1, but on the stage 2 amount participants decreased and I was only the 379th of 816 with 0.417 score on the final dataset. But the result in my profile is calculated using full amount of participants, so I'm shown as entered the top 11%
Another competition, I was planning to take part in, was ML track on Yandex Algorithm 2018, that was held from March 30 to April 23:

It strongly overlapped by time with the Data Science Bowl, so the main problem for me was that after finishing Kaggle competition I had only two weeks for Yandex ML, and I was greatly tired. In contrast with IDAO, I'm dissatisfied with the place I've managed to get. It was about 119 of 150-160 on the stage 1 and I was totally waned and decided even not to prepare submission for the stage 2.
The task itself was said to be prepared by Alice Yandex team, and it was about natural language processing (NLP) for dialogue systems. Its meaning was to pick up the most suitable answer for the given dialog context. There are two approaches for such kind of tasks, the generative and search-based. The first one suppose that the machine creates an answer, picking words just like human intelligence does. The search-based approach uses a database with ready phrases and select the most suitable answer from one of the found candidates. ML Track was about the second approach.
The was a list of dialogs created from OpenSubtitles dataset, with movie subtitles. Each dialog has from one to three "context" phrases and six "candidate" answers. The answers were marked by assessors and were assigned the level of compliance: good, neutral or bad. Each mark was also supplemented by a number, reflecting how confident the assessors were in their evaluation.
Schematically, it looked like this:
personage A: <context phrase 1>
personage B: <context reply 2>
personage A: <contex reply 3>
personage B: ???
Personage B candidate answers:
In the beginning I was going to use the Word2Vec library, but we had a seminar and a homework in DMiA about ELMO model, so I decided to combine two activities in one. We were forewarned what ELMO does not show high result with Russian language, so may be that was the reason for my low place. However, I think my tiredness was much more guilty. I had no desire neither to tune the model, nor to try another approach.
However, the good point in this competition was what I got a little more familiar with Pandas. Working with this library is really «must have» skill.
For now, I'm not planning to participate in any competitions or attend other courses in the next few months, because I want to learn some things by myself. Moreover, I've missed a couple of topics in DMiA, and have to overtake them. It seems to be a good idea to look attentively at a Mask R-CNN implementation that I was using on Kaggle and read about the winning team's solution as well. And also I've visited one conference and wanted to refresh some its points in memory. I was going to attend another, more serious, conference, the Data Fest, but there were reasons that didn't allowed me to. There should be video-records from it, i guess, so I hope to learn them too. And fuck, I'm still feell myself tired a little bit
So, that's it!
Participation in the first was obligatorily as a homework on the free courses Data Mining in Action that I have been attending recently. The competition was held on the popular Kaggle platform and was called Data Science Bowl 2018:
Well, I will post one more picture from the competition:
The task was to train an algorithm that automatically locates the nuclei on the microscope photos of biological cells. It should help in the medicine, allowing to develop new drugs faster and treat diseases more effectively.
The level that was required by our homework at first looked very ambitious, as we have to achieve 0.45 metric score. Sure, this number itself does not telling a lot. So, to explain, there were about ~3000 participants in the stage 1. Places of those who earned 0.45 and higher were starting from about ~200. Thus, 200/3000 ~= 0.067. How does it sound to get into the top 6% of huge international Deep Learning competition on the most popular data science platform?
The reality turned out to be not so scary. In fact, Kaggle is not only a competitive platform but also a great place for information exchange and education. Many participants share their solutions, approaches and ideas. Our courses' organizers recommended us to use one of the available models, configure it by ourself and train it up to the desired level. They pointed out a model that gave required scores for sure, the custom implementation of Mask R-CNN architecture, proposed by Facebook Research. Though the choice was not limited to this only variant, I've decided not to risk and took this implementation. Apart from this and others realizations of Mask R-CNN, one more architecture that showed high results was U-Net, often used for biological tasks. (And that was the architecture used by the won team).
Thus, my aim was to set up the code and make it run, not to develop the algorithm from the beginning. However, this task is not done in three clicks too!
Training neural networks for computer vision is very computationally intensive. It is not usually performed on the CPU, but rather on powerful GPU, with such technologies as NVIDIA CUDA. My simple home computer just has not the capacities required. For other homeworks we used to work with Google Colaboratory. It is absolutely free online tool, but it is a little bit limited. I found no opportunity to handle the environment in a custom way, to install libraries from sources and to build extensions. Every twelve hours the runtime is reset, and you have to perform the setup from the beginning. And also, there can be technical failures, as in many other free resources.
The only decision that I saw, was to turn to cloud computing and rent a virtual machine. Amazon has images specialized for deep learning, having a lot of useful frameworks preinstalled. They are called Amazon Deep Learning AMI. Such virtual machines are not free, with per-hour fee, but when you are participating in a popular competition, there's no surprise that you have to pay.
It took several days and a fair amount of brainwork to install the solution, to tune the code and to train the model, however I've managed to get the needed score:
It cost me about $60, and the unpleasant thing was that 18% (almost one fifth!) of this sum was just the VAT, the tax that I had to pay in favor of the Russian Federation. What for? What Value-Added it was? I was just using the service of a foreign company in educational purpose, to learn how to solve a biomedical task. For me it looks like a punishment for Russian citizenship from Russian country. Here can be added the recent appreciation of the dollar along with Roskomnadzor blocking bunches of Amazon IP addresses. And the prohibition of Telegram, where our courses' chats lived. Are my thoughts to leave this place really unjustified?
The DMiA's teachers fucked up with the deadline a little. They declared that the homework had to be finished until the 17th of April, the next day of the competition end. However, the competition had two stages, and scores on the leaderboard were shown only for the first one. The second stage scores became available only when the stage ended, so there were no possibility to make sure that you managed to get the needed level. Thus, the deadline was denounced as 17th of April, but in fact it was the 11th of April, and that was discovered not so early. We've discussed it n the group chat, I've finished my work in time and not sure if anyone else was affected, but that was not a good situation. Yeah, it's IT, shit happens here constantly, I know.
Even Kaggle competition organizers make mistakes. There was a paragraph in the rules that stated: «Stage one deadline and stage two data release: April 11, 2018 - PLEASE NOTE: If you do not make a submission during the second stage of the competition, you will not appear on the final competition leaderboard and you will not receive competition ranking points». There was also mentioned that the participants have to finalize their models till April 11 - and no clarification, that did it mean. So I've uploaded answers for stage 1, uploaded answers to stage 2, and only after the competition ended I've learned that we had to upload the model source code as well - otherwise such participants were removed from the final list. Fortunately, I was not the only sufferer, there were a lot of complaints. Organizers agreed that it was their fault and restored all the places.
I've counted to stay int the "bronze" area, as I was there on the stage 1, but on the stage 2 amount participants decreased and I was only the 379th of 816 with 0.417 score on the final dataset. But the result in my profile is calculated using full amount of participants, so I'm shown as entered the top 11%
Another competition, I was planning to take part in, was ML track on Yandex Algorithm 2018, that was held from March 30 to April 23:
It strongly overlapped by time with the Data Science Bowl, so the main problem for me was that after finishing Kaggle competition I had only two weeks for Yandex ML, and I was greatly tired. In contrast with IDAO, I'm dissatisfied with the place I've managed to get. It was about 119 of 150-160 on the stage 1 and I was totally waned and decided even not to prepare submission for the stage 2.
The task itself was said to be prepared by Alice Yandex team, and it was about natural language processing (NLP) for dialogue systems. Its meaning was to pick up the most suitable answer for the given dialog context. There are two approaches for such kind of tasks, the generative and search-based. The first one suppose that the machine creates an answer, picking words just like human intelligence does. The search-based approach uses a database with ready phrases and select the most suitable answer from one of the found candidates. ML Track was about the second approach.
The was a list of dialogs created from OpenSubtitles dataset, with movie subtitles. Each dialog has from one to three "context" phrases and six "candidate" answers. The answers were marked by assessors and were assigned the level of compliance: good, neutral or bad. Each mark was also supplemented by a number, reflecting how confident the assessors were in their evaluation.
Schematically, it looked like this:
personage A: <context phrase 1>
personage B: <context reply 2>
personage A: <contex reply 3>
personage B: ???
Personage B candidate answers:
| Candidate | Compliance | Confidence |
| answer 1 | good | 0.9864 |
| answer 2 | good | 0.8567 |
| answer 3 | good | 0.5734 |
| answer 4 | neutral | 0.9356 |
| answer 5 | bad | 0.9756 |
| answer 6 | bad | 0.756 |
In the beginning I was going to use the Word2Vec library, but we had a seminar and a homework in DMiA about ELMO model, so I decided to combine two activities in one. We were forewarned what ELMO does not show high result with Russian language, so may be that was the reason for my low place. However, I think my tiredness was much more guilty. I had no desire neither to tune the model, nor to try another approach.
However, the good point in this competition was what I got a little more familiar with Pandas. Working with this library is really «must have» skill.
For now, I'm not planning to participate in any competitions or attend other courses in the next few months, because I want to learn some things by myself. Moreover, I've missed a couple of topics in DMiA, and have to overtake them. It seems to be a good idea to look attentively at a Mask R-CNN implementation that I was using on Kaggle and read about the winning team's solution as well. And also I've visited one conference and wanted to refresh some its points in memory. I was going to attend another, more serious, conference, the Data Fest, but there were reasons that didn't allowed me to. There should be video-records from it, i guess, so I hope to learn them too. And fuck, I'm still feell myself tired a little bit
So, that's it!
@темы: Программирование, english writing skills, Data Science, Machine Learning
-
-
30.04.2018 в 19:17About VDA ant Telegram - really embarassing(
-
-
30.04.2018 в 21:16Do you use Telegram too?
-
-
01.05.2018 в 11:24-
-
01.05.2018 в 21:18-
-
01.05.2018 в 21:40-
-
02.05.2018 в 12:24